
Bad News, DBAs, We Are All Developers Now
I sometimes joke that I’m a Junior Developer and a Principal Database Administrator, which is why I have a Staff level title. I’m not sure …
Read MoreWe’ve recently updated the SQL Server and Azure SQL index architecture and design guide. This article is an in-depth guide to indexing in databases using the SQL Server engine, including SQL Server, Azure SQL Database, Azure SQL Managed Instance, and Azure Synapse Analytics.
Our recent update adds a table to categorize the types of indexes discussed in the article, clarifies B-trees vs B+ trees, and describes how row locators (aka “secret columns”) are used in nonclustered indexes.
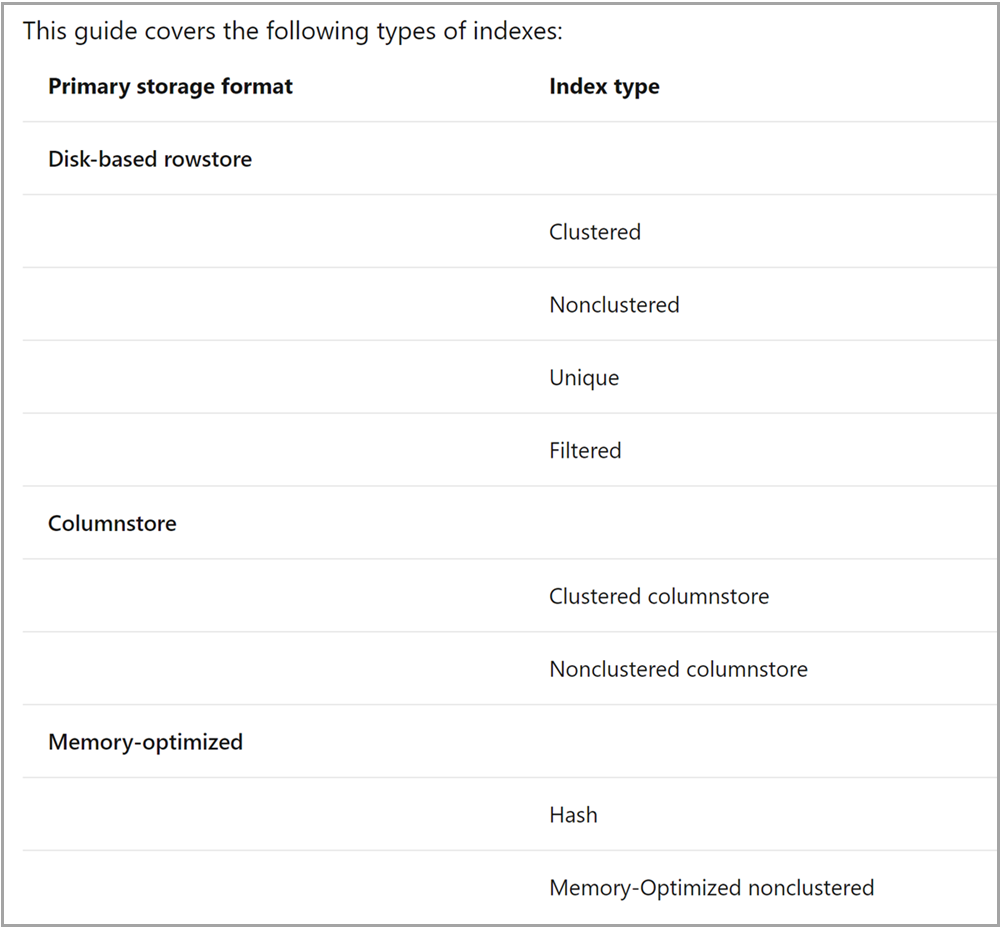
The index architecture and design guide now opens with a table describing the types indexes discussed in the article, grouped by their primary storage format: disk-based rowstore indexes, columnstore indexes, and memory-optimized indexes.
This is a small change, but I hope it proves helpful to folks who are newer to this topic and who may find themselves confused by different uses of the word ’nonclustered’, or who want a big-picture view of the most commonly used index types.
A customer submitted an issue asking us to clarify when the SQL Server engine uses B-trees vs B+ trees. Up to this point, the documentation for SQL Server and Azure SQL has largely used the general term “B-tree” without being more specific.
My colleague Mike Ray (Twitter) took on this project, which was a considerable amount of work: there are a lot of articles which mention B-trees. Most of these articles shouldn’t go into a deep discussion of types of B-trees, however. Mike identified these articles (for example, the CREATE INDEX (Transact-SQL) article) and added the following note:
SQL Server documentation uses the term B-tree generally in reference to indexes. In rowstore indexes, SQL Server implements a B+ tree. This does not apply to columnstore indexes or in-memory data stores. Review SQL Server Index Architecture and Design Guide for details.
Mike worked with Pedro Lopes (Twitter) to update the index architecture and design guide to clarify when B+ indexes are used (disk-based rowstore indexes, the deltastore for columnstore indexes) and when other variations of B-trees are used (a Bw-tree is used in In-Memory nonclustered indexes).
Together, these changes should not only help folks who are interested in B-trees, but also will help raise awareness of the index architecture and design guide itself as a great free resource for learning about indexing.
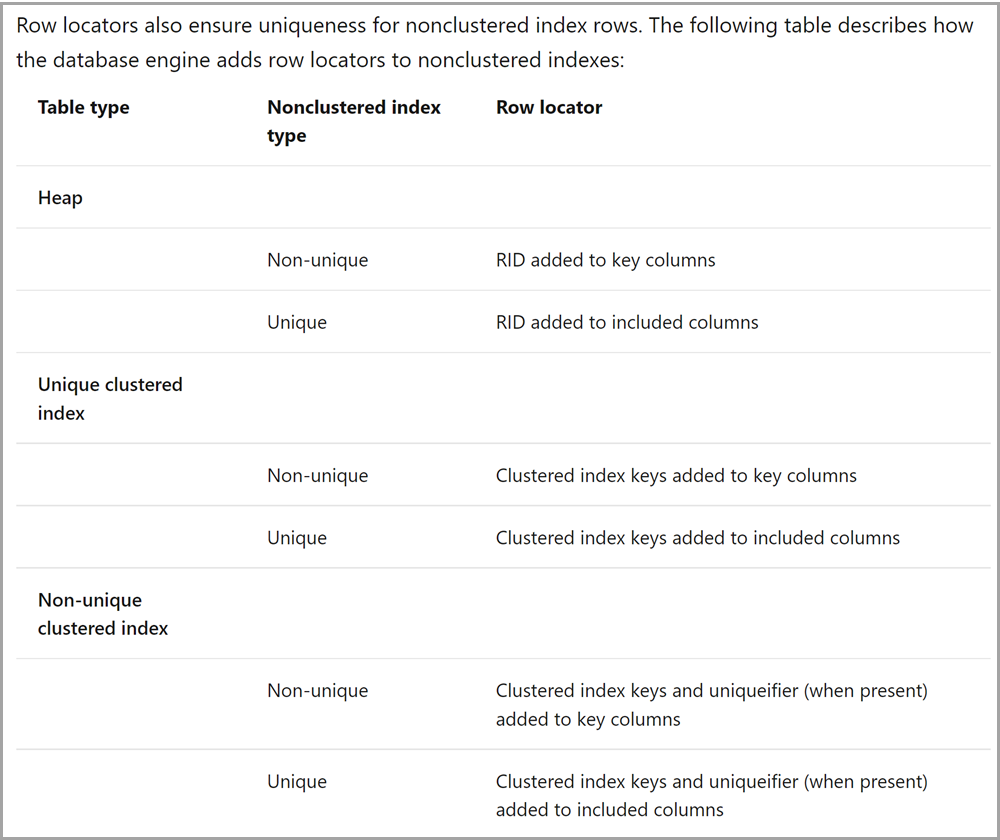
Another customer submitted an issue asking us to document how and why the SQL Server Engine adds clustered index keys to nonclustered indexes.
Based on this request, I worked with Pedro to add information to the nonclustered index architecture section of the design guide.
We went a little broader than the request, because if a disk-based rowstore table does not have a clustered index (in other words, if it is a heap), then a row locator is still added to nonclustered indexes. We added the following table, along with a table of specific examples.
And, importantly, we added the following sentence:
Clustered index key-based row locator columns in a nonclustered index can be used by the query optimizer, regardless of whether they were explicitly specified in the index definition.
Thanks very much to my colleagues Mike Ray (Twitter) and Pedro Lopes (Twitter) for their efforts in helping make the SQL Server and Azure SQL index architecture and design guide even better.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.