Azure SQL Managed Instance Memory-to-Core Math Still Doesn't Work, Even in GPv2
Microsoft recently announced that Azure SQL Managed Instance Next-gen General Purpose (GPv2) is generally available. GPv2 brings significant storage …
Read MoreI found a nasty bug in SQL Server and Azure SQL Managed Instance recently: sometimes an ‘online’ index rebuild of a disk-based rowstore clustered index (basically a normal, everyday table) isn’t actually ‘online". In fact, it’s very OFFLINE, and it blocks both read and write queries against the table for long periods.
If you manage to make it through a rebuild successfully, the problem goes away for future rebuilds of that clustered index – likely leaving you bruised and bewildered.

This bug isn’t related to the schema modification lock (SCH_M) taken out briefly at the end of an online index operation. That’s documented, and risks of that can be mitigated with the WAIT_AT_LOW_PRIORITY setting. This post describes and has a repro script for exclusive (X) locks held for long periods through the duration of the supposedly online operation. The WAIT_AT_LOW_PRIORITY setting offers no protection for these locks in my testing. I am also only discussing examples that drop newer types of LOB columns – my repro script uses NVARCHAR(max), and the problem also happens with VARBINARY(max).
I can reproduce this problem when rebuilding a clustered index online after dropping a large object column (LOB) from the table. The problem happens even if DBCC CLEANTABLE has been run to clean up LOB table from removed columns already.
What should happen is that the ALTER INDEX ... REBUILD WITH (ONLINE=ON) command should return an error if the operation can’t be performed online. And there should be a published way to detect or understand when online index operations aren’t available. but this isn’t the case. Instead, the supposedly “online” command runs very slowly and takes out exclusive locks. Depending on your environment, that might cause some big old problems.
This diagram from the How online index operations work article is helpful in understanding the locks that should be taken out in an online index operation for a disk based rowstore table:
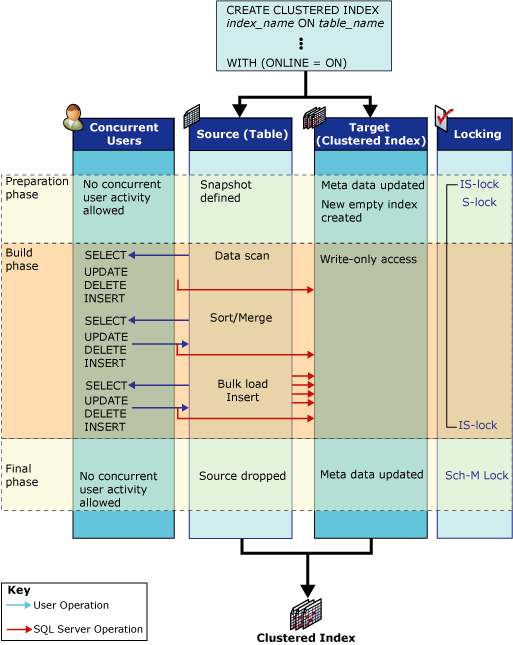
To reiterate, this is Microsoft’s diagram from How online index operations work, and is not my own work.
Note that there aren’t any exclusive (X) locks in this diagram.
As Microsoft’s documentation says:
We recommend performing online index operations for business environments that operate 24 hours a day, seven days a week, in which the need for concurrent user activity during index operations is vital.
Online index rebuilds are only available in Expensive editions of SQL Server: Enterprise and Azure SQL. In my personal experience, online index rebuilds are one of the major features that sell licenses for those Expensive editions – while REORGANIZE commands can be performed online, they are fairly limited and are generally quite slow.
A bug in a major feature that sells those Expensive licenses is a pretty big deal. It’s not uncommon to use large object columns, and it’s also not uncommon to want to drop those columns once the data becomes unwieldy.
I’m quite surprised that this problem appears to have existed in SQL Server since 2020 and is reported to be a known issue by Microsoft Support since May 2021. I haven’t found this documented by Microsoft. I would expect this limitation to be listed in Guidelines for online index operations, Perform index operations online, and How online index operations work, but I can’t find a mention anywhere.
It is possible that the bug was fixed before and has recurred. Or it’s documented someplace I haven’t found yet. But it seems like a sad situation.
I’ve reproduced this problem in two environments: SQL Server 2022 Developer Edition and Azure SQL Managed Instance. The Stack Exchange post above mentions Azure SQL Database having the problem, but I haven’t verified that myself.
Feel free to use my script below as the basis to check out other versions of SQL Server if you’d like.
I’ve been able to reproduce this problem with the script below. I haven’t tested a bunch of variations of the scripts with different table schemas, data types, etc, simply because time is scarce. I’m writing this at 9 pm and I still have raccoon drawings to color and shade before the post is done. (Priorities.)
Basically, this could happen only under the scenario I have described below, or it could also happen under other scenarios as well. Feel free to use the script as a start for your own testing and explore more.
Setup: download and install the free diagnostic stored procedure, sp_WhoIsActive.
Next, create a little test database if you want. I used compat level 160 because i wanted to use GENERATE_SERIES() later on. I’ve seen this in compat level 150 as well.
CREATE DATABASE DropLOBColumnTest;
GO
USE DropLOBColumnTest
GO
SET NOCOUNT ON;
GO
ALTER DATABASE DropLOBColumnTest SET COMPATIBILITY_LEVEL=160;
GO1. Create a table, dbo.LOBTest
I am making a questionable choice and using FILLFACTOR=1. The bug can absolutely happen with a fillfactor of 100%. I am lazy and I wanted a way to create a bunch of in-row data pages without actually having to calculate a bunch of data to fill them in, so I did that. Follow your heart and change it if you like.
DROP TABLE IF EXISTS dbo.LOBTest;
GO
CREATE TABLE dbo.LOBTest (
i integer identity NOT NULL,
j char(5000) NULL,
k nvarchar(MAX),
l nvarchar(MAX),
CONSTRAINT cpk_lob PRIMARY KEY CLUSTERED (i) WITH (FILLFACTOR=1)
);
GO2. Add some data to dbo.LOBTest
How much data depends on what type of database you are using and how patient you are. On Azure SQL Managed Instance, I used “GO 10” and could reproduce the issue. On my laptop I went ahead and did 50 rounds because it’s much faster.
INSERT dbo.LOBTest (j,k,l)
SELECT 1, REPLICATE('a',4001), REPLICATE('a',4001)
FROM GENERATE_SERIES(1, 10000) AS g
--GO 10
GO 503. Check how much data is in dbo.LOBTest
This table is measured by weight, not by volume.
SELECT
t.NAME AS TableName,
CASE i.index_id WHEN 0 THEN 'heap' ELSE 'clustered' END AS TableType,
i.index_id,
a.type_desc,
CAST(SUM(a.total_pages) * 8. / 1024./1024. AS numeric(10,1)) AS SizeGB,
SUM(p.rows) AS [Rows]
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME = 'LOBTest'
AND i.index_id=1
AND a.total_pages > 0
GROUP BY
t.Name, i.index_id, a.type_desc
ORDER BY SizeGB desc;
GOI have 7.6GB of LOB data and 3.8GB of in row data.

3. Drop one of the LOB columns from dbo.LOBTest
Goodbye, column k:
ALTER TABLE dbo.LOBTest DROP COLUMN k;
GO4. Check how much LOB data you have now (spoiler: it’s the same)
Run the query above to check how much data is in the table. You should see the same amount. When you drop a LOB column, the space isn’t deallocated.
There are two ways to get the space back: DBCC CLEANTABLE or a clustered index rebuild. (I’ve tested DBCC CLEANTABLE and it doesn’t fix this issue, but feel free to reproduce that if you want.)
Even if you don’t want to reclaim the space, eventually your index may become fragmented enough that it qualifies for a rebuild in a maintenance job.
5. Create and start an XEvents trace
We are creating this trace for two reasons:
A. The trace is going to slow our instance down a lot because tracing locks is slloooowwww. So don’t do this on an instance where you care about performance. It’s actually handy for this to be slow because it gives you time to start up a read query that will be blocked and inspect the situation with sp_WhoIsActive without having to rush too much.
B. The trace information is somewhat useful. We could filter it more, but see A.
First, SELECT @@SPID to find the session ID you’re going to use to rebuild the index. Then specify that session id in the trace definition.
SELECT @@SPID;
CREATE EVENT SESSION [Locks] ON SERVER
ADD EVENT sqlserver.lock_acquired(
ACTION(package0.process_id,sqlserver.database_name,sqlserver.sql_text,sqlserver.tsql_stack)
WHERE ([sqlserver].[session_id]=(52))),
ADD EVENT sqlserver.lock_released(
ACTION(package0.process_id,sqlserver.database_name,sqlserver.sql_text,sqlserver.tsql_stack)
WHERE ([sqlserver].[session_id]=(52)))
ADD TARGET package0.ring_buffer
WITH (MAX_MEMORY=8192 KB,EVENT_RETENTION_MODE=NO_EVENT_LOSS,MAX_DISPATCH_LATENCY=5 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=PER_CPU,TRACK_CAUSALITY=ON,STARTUP_STATE=OFF);
GO
ALTER EVENT SESSION Locks ON SERVER STATE=START;
GO6. Rebuild that index “online”
Now run:
ALTER INDEX cpk_lob ON dbo.LOBTest REBUILD WITH (ONLINE=ON);
GO7. Try to query the table in another session
In another session, run:
SELECT COUNT(*) FROM dbo.LOBTest;8. Look in horror upon your lock waits with sp_WhoIsActive
In a third session, run:
EXECUTE sp_WhoIsActive @get_locks=1;Here’s what you should see: Your supposedly online index rebuild blocking your select query, which is waiting with a LCK_M_IS lock wait:

If you open the XML column for the locks for the ALTER INDEX statement, you should see that the ALTER INDEX statement has been granted an X (exclusive) object lock on dbo.LOBTest. There are also a bunch of exclusive page locks– in this case 233,345 of them.

9. What’s in that XEvents trace?
There’s a whole lot of locks in there, and among them you will see some X locks. Here’s the one on the object:
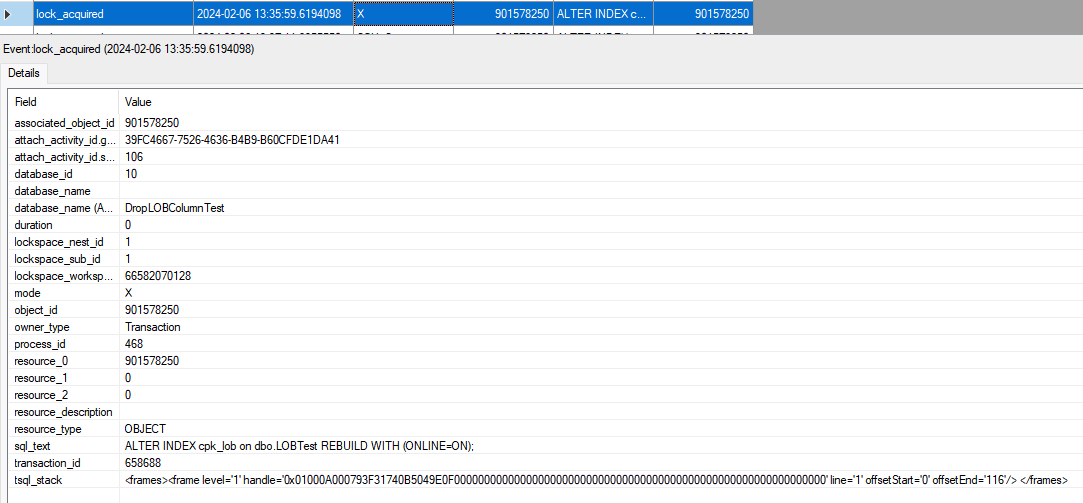
10. Stop and drop that trace
Goodbye, trace.
ALTER EVENT SESSION Locks ON SERVER STATE=STOP
GO
DROP EVENT SESSION Locks ON SERVER
GOYou might wonder, what do you do if you have a very large table and you can’t take an outage window to rebuild the clustered index offline?
Yeah, I wonder that, too.
You can run DBCC CLEANTABLE to try to release some space.
And you can exclude the clustered index from your index maintenance jobs, or configure it to only have REORGANIZE operations, not REBUILDS. Ever. (I’ve only tested this briefly– the REORGANIZE operation does take out X locks, but in smaller/briefer batches and regularly releases them. I wouldn’t swear to that, though, it was just a quick test.)
Aside from that, I really don’t know.
Can you run a query to detect if any of your tables have had LOB columns dropped and are in a state where they might be prone to this issue? If you can, I haven’t figured out how yet.
Hopefully this will get fixed before another couple of years elapse – but I fear that note that was added to the documentation means it likely won’t.


Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.