
How To: Automate Continuous SQLServer Activity with Stored Procedures and Powershell Jobs
It’s often useful to be able to run a bunch of stored procedures in the background over a period of time against a test instance.
Read MoreIn A Previous Installment… our heroine (that’s me) rediscovered CTEs, specifically in the recursive style. That was in my post “Filling in Data Potholes with Recursive CTEs.”

To recap: I was working on a problem with gaps in temporal data. The basic scenario was:
Imagine that you are writing a script that looks at data grouped by the minute. You notice that there are no rows for some minutes, and you’d like to display a value when that is the case, probably showing a count of zero.
For the particular problem I was looking at, I was using small datasets and generating a list of all the valid dates with a recursive CTE performed well for me.
The best thing about blogging is not really sharing what you know: it’s getting to learn more. You get to learn from the process of writing the blog, and also if you are lucky enough to get comments from readers.
I had a couple of comments that mentioned performance, and Brad Shulz ( blog | sadly not on Twitter ) also linked me up to this most interesting post he did on recursion.
Brad’s comment and post inspired me to do a little rewriting to put together a tally table style solution to the example I gave, scale it out in a few different ways, and collect and publish performance comparisons.
Why? Well, it’s interesting.
I didn’t do anything fancy for this. I took the same query I had previously to generate some data with gaps, and just modified it a bit so I could add in a small amount of data three months out, six months out, one year out, and two years out. This created datasets that were mostly “gap” for these future periods, but still made the query return a lot of rows.
--Run this with @monthOffset values: 0, 3, 6, 12, 24 --Run a trial each time. DECLARE @monthOffset TINYINT = 0
--Let's create some data with some gaps
DECLARE @startDate DATETIME2(0)= DATEADD(MM, @monthOffset, '1/1/2011')
IF OBJECT_ID('dbo.MyImperfectData', 'U') IS NOT NULL AND @monthOffset = 0 BEGIN DROP TABLE dbo.MyImperfectData END
IF OBJECT_ID('dbo.MyImperfectData', 'U') IS NULL
CREATE TABLE dbo.MyImperfectData
( ItemDate DATETIME2(0) ,
ItemCount SMALLINT ,
CONSTRAINT cx_ItemDate_MyImperfectData UNIQUE CLUSTERED ( ItemDate )
)
INSERT dbo.MyImperfectData ( ItemDate, ItemCount )
VALUES ( DATEADD(mi, 0, @startDate), 12 ), ( DATEADD(mi, 1, @startDate), 3 ),
( DATEADD(mi, 2, @startDate), 6 ), ( DATEADD(mi, 3, @startDate), 12 ),
( DATEADD(mi, 4, @startDate), 24 ), ( DATEADD(mi, 5, @startDate), 1 ),
/* Gap where 6 would be */
( DATEADD(mi, 7, @startDate), 122 ), ( DATEADD(mi, 8, @startDate), 1 ),
( DATEADD(mi, 9, @startDate), 1244 ), ( DATEADD(mi, 10, @startDate), 23 ),
( DATEADD(mi, 11, @startDate), 12 ), ( DATEADD(mi, 12, @startDate), 24 ),
( DATEADD(mi, 13, @startDate), 27 ), ( DATEADD(mi, 14, @startDate), 28 ),
/* Gap where 15, 16, 17 would be */
( DATEADD(mi, 18, @startDate), 34 ), ( DATEADD(mi, 19, @startDate), 93 ),
( DATEADD(mi, 20, @startDate), 33 ), ( DATEADD(mi, 21, @startDate), 65 ),
( DATEADD(mi, 22, @startDate), 7 ), ( DATEADD(mi, 23, @startDate), 5 ),
/* Gap where 24 would be */
( DATEADD(mi, 25, @startDate), 4 ), ( DATEADD(mi, 26, @startDate), 6 ),
( DATEADD(mi, 27, @startDate), 7 ), ( DATEADD(mi, 28, @startDate), 77 ),
( DATEADD(mi, 29, @startDate), 94 ) ;For this test I created a temporary tally table with two million rows. I used the method to populate the table which Jeff Moden recommends in his article, The ‘Numbers’ or ‘Tally’ Table: What it is and how it Replaces a Loop:
IF OBJECT_ID('tempdb..#tally') IS NOT NULL
DROP TABLE #tally
BEGIN
SELECT TOP 2000000
IDENTITY( INT,1,1 ) AS N
INTO #Tally
FROM Master.dbo.SysColumns sc1 ,
Master.dbo.SysColumns sc2
CREATE UNIQUE CLUSTERED INDEX cx_Tally_N ON #Tally(N)
ENDOne thing to note with the tally table approach: you need to make sure you have enough numbers in the tally table to support your needs, or you’ll be missing rows in results. For production usage, you probably want to go well above 2 million if you’re using this for any scale.
To create the tally table on the fly with this number of rows, it took 4,438 ms of CPU time.
For fun, I used a CTE when I wrote my query to display the data for the Tally table, also. In this case, it’s just not a recursive CTE. A derived table could have been used just as well, but I think it’s more readable with the CTE.
WITH TallyCTE
AS ( SELECT DATEADD(mi, t.N, limits.MinDate) AS dayDate
FROM #Tally t
JOIN ( SELECT MIN(ItemDate) AS MinDate ,
MAX(ItemDate) AS MaxDate
FROM dbo.MyImperfectData AS imd
) limits ON t.N <= DATEDIFF(mi, MinDate, MaxDate)
)
SELECT tcte.dayDate ,
CASE WHEN Itemcount IS NULL THEN '[Missing Row]'
ELSE ''
END AS ColumnDescription ,
COALESCE(ItemCount, 0) AS ItemCount
FROM TallyCTE tcte
LEFT OUTER JOIN dbo.MyImperfectData AS d ON tcte.dayDate = d.ItemDate
ORDER BY tcte.dayDateThis was the same as last time– just recapping it here for anyone playing along at home:
DECLARE @startDate DATETIME2(0) ,
@endDate DATETIME2(0) ;
SELECT @startdate = MIN(ItemDate), @endDate = MAX(ItemDate)
FROM dbo.MyImperfectData ;
WITH MyCTE
AS ( SELECT @startDate AS MyCTEDate
UNION ALL
SELECT DATEADD(mi, 1, MyCTEDate)
FROM MyCTE
WHERE MyCTEDate < DATEADD(mi, -1, @endDate) )
SELECT MyCTEDate, CASE WHEN Itemcount IS NULL THEN '[Missing Row]'
ELSE ''
END AS ColumnDescription,
COALESCE(ItemCount, 0) AS ItemCount
FROM MyCTE
LEFT OUTER JOIN dbo.MyImperfectData ld
ON MyCTE.MyCTEDate = ld.ItemDate
ORDER BY MyCTEDate
OPTION ( MAXRECURSION 0 ) ;I tested this on a virtual machine on my laptop, which is (definitely) not a production environment! However, I wasn’t doing much else on the laptop at the time, and I ran each test a couple of times to make sure results were all clearly in the right ballpark. I cleaned out the buffer pool (DBCC DROPCLEANBUFFERS) and the procedure cache (DBCC FREEPROCCACHE) before each query.
Here is what I saw:
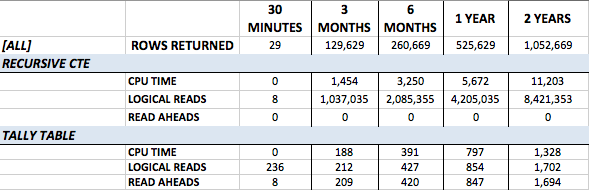
Don’t forget that I was seeing 4,438 ms of CPU time to create my tally table itself– if you truly couldn’t persist objects, this might be a concern for you. However, the numbers in this table really justify creating persisting the tally object permanently.
CPU time is 8 times faster on average with the tally method when we get above 125K rows. The minimal logical reads, and the ability for read-ahead reads to be used, is also convincing.
For the most part, I’m just going to link yet again to Brad’s post. Read about the Stack Spool operator!
But I will note this: when I looked at execution plans for this, I noticed that subtree cost estimates for the CTE query were .0148, and estimates for the tally table approach were 61.848. (This is from the two year batch.) The statistical estimates from the tally table approach were just far more accurate. This makes perfect sense, as the optimizer had statistics available to it to help it out: they were on the Tally table itself.
I can’t really think of a situation in which I’ll use the recursive CTE for this specific issue. And after thinking about the stack spool operator, I’ll try to think differently about how to construct queries in general.
However, I really enjoyed writing these posts.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.