Adaptive Joins and Memory Grants in SQL Server
Adaptive joins let the optimizer choose between a Hash Join and a Nested Loop join at runtime, which can be fantastic for performance when row count …
Read MoreExecution plans got a cool new piece of diagnostic information in SQL Server 2012 SP3, SQL Server 2014 SP2, and SQL Server 2016: “Number of Rows Read”. In fancy language, this is “better diagnostics” when a query plan has “residual predicate pushdown” (KB 3107397).
In human language, SQL Server will now tell you “How many rows did I really have to read, even if I have a hidden filter in here?”
This appears in actual execution plans only. Sorry, there is no such thing as “Estimated Number of Rows Read” that I can find. Let’s take a look and see it in action.
We’re making a table with 1000 rows. 999 rows have firstname=‘Kendar’ and lastname=‘Little’. Only one row has firstname=‘Jeremiah’ and lastname=‘Peschka’.
SET NOCOUNT ON;
GO
IF OBJECT_ID(N'actualrowstest') IS NOT NULL
DROP TABLE dbo.actualrowstest;
GO
CREATE TABLE dbo.actualrowstest (
imakeywhatever INT IDENTITY not null,
firstname varchar(256) DEFAULT ('Kendar'),
lastname varchar(256) DEFAULT ('Little'),
CONSTRAINT pk_actualrowstest PRIMARY KEY CLUSTERED (imakeywhatever)
)
GO
INSERT dbo.actualrowstest DEFAULT VALUES;
GO 999
INSERT dbo.actualrowstest VALUES ('Jeremiah','Peschka');
GOAll our tests are going to use one nonclustered index, which is on firstname, lastname:
CREATE INDEX ix_actualrowstest_firstname_lastname ON dbo.actualrowstest (firstname, lastname);
GOWe run a query that can use the nonclustered index, but it’s not perfect for it. We want to find every row where lastname=‘Peschka’:
SELECT firstname
FROM dbo.actualrowstest
WHERE lastname='Peschka';
GOOur index looks like this:
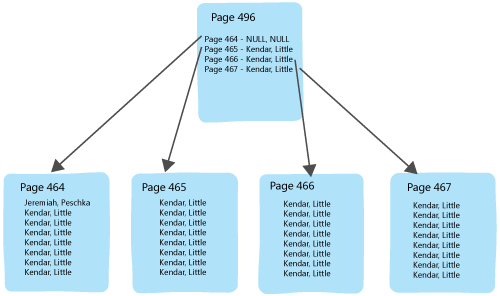
Everything is sorted by firstname, then by lastname. Every column that the query wants is here, but the optimizer doesn’t know if perhaps there’s a row at the end of this table for “Kendar, Peschka”. It has to check all 1000 rows in a scan to find that single row.
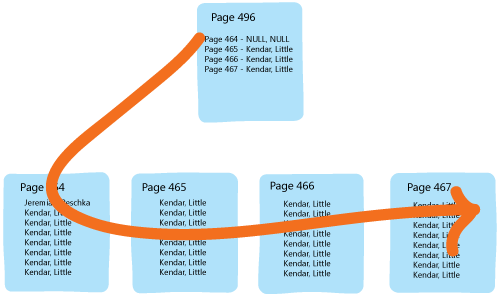
Here’s what the execution plan for our query looks like. We can see that it’s a scan, but that narrow line coming out of the scan is misleading.
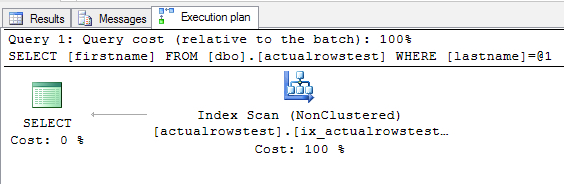
If we hover over that line we can see that it estimated it’d return 1 row (and it was right). But before this improvement, we couldn’t see how many rows it actually READ to find that data. One row isn’t so bad, is it?
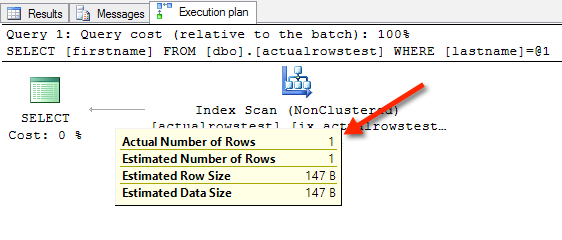
If you hover over the properties of the scan itself, you can now see the number of rows read to output that single row. That’s awesome, because in some cases we might have scanned a million rows. Or a hundred million rows. We couldn’t tell from just the actual plan, before this!
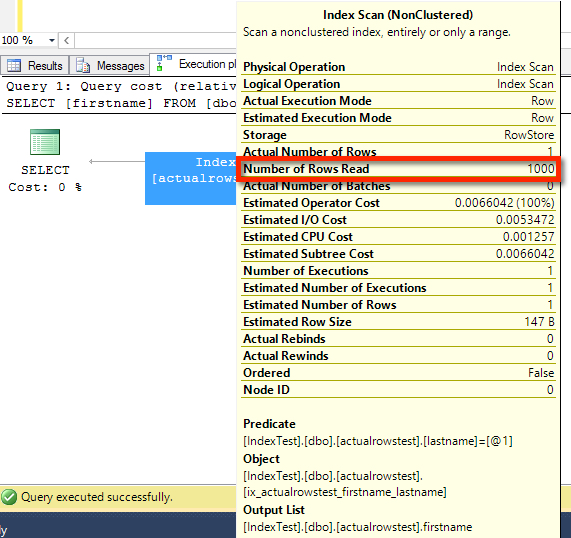
Look at the bottom of that tooltip. See how it says “Predicate”, and says [IndexTest].[dbo].[actualrowstest].[lastname]=[@1]?
That’s a hidden filter. Or in those fancy terms in the KB, “residual predicate pushdown” has occurred – instead of having the scan dump all the rows into a separate filter operator, it snuck it in here.
If our query were looking for firstname=‘Jeremiah’, then we would have an Index Seek operator only, and the plan would show a “Seek Predicate”. In that case, “Number of Rows Read” doesn’t appear in the plan because the value would just be the same as “Actual Number of Rows.” In other words, you’ll only see this in your plans if you have a plain old “Predicate” (aka hidden filter) on an operator.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.