Adaptive Joins and Memory Grants in SQL Server
Adaptive joins let the optimizer choose between a Hash Join and a Nested Loop join at runtime, which can be fantastic for performance when row count …
Read MoreJoins can be tricky. And where you put your ‘where’ clause may mean more than you think!
Take these two queries from the AdventureWorksDW sample database. The queries are both looking for data where SalesTerritoryCountry = ‘NA’ and they have the same joins, but the first query has a predicate on SalesTerritoryCountry while the second has a predicate on SalesTerritoryKey.
/* Query 1: Predicate on SalesTerritoryCountry */ select ProductKey, OrderDateKey, DueDateKey, ShipDateKey, CustomerKey, PromotionKey, CurrencyKey, fis.SalesTerritoryKey, SalesOrderNumber, SalesOrderLineNumber, RevisionNumber, OrderQuantity, UnitPrice, ExtendedAmount, UnitPriceDiscountPct, DiscountAmount, ProductStandardCost, TotalProductCost, SalesAmount, TaxAmt, Freight, CarrierTrackingNumber, CustomerPONumber, OrderDate, DueDate, ShipDate from dbo.FactInternetSales fis join dbo.DimSalesTerritory st on fis.SalesTerritoryKey=st.SalesTerritoryKey where st.SalesTerritoryCountry = N’NA’ GO
/* Query 2: Predicate on SalesTerritoryKey (for the exact same country) */ select ProductKey, OrderDateKey, DueDateKey, ShipDateKey, CustomerKey, PromotionKey, CurrencyKey, fis.SalesTerritoryKey, SalesOrderNumber, SalesOrderLineNumber, RevisionNumber, OrderQuantity, UnitPrice, ExtendedAmount, UnitPriceDiscountPct, DiscountAmount, ProductStandardCost, TotalProductCost, SalesAmount, TaxAmt, Freight, CarrierTrackingNumber, CustomerPONumber, OrderDate, DueDate, ShipDate from dbo.FactInternetSales fis join dbo.DimSalesTerritory st on fis.SalesTerritoryKey=st.SalesTerritoryKey where st.SalesTerritoryKey = 11; GO
Take a look at the difference in their estimated execution plans: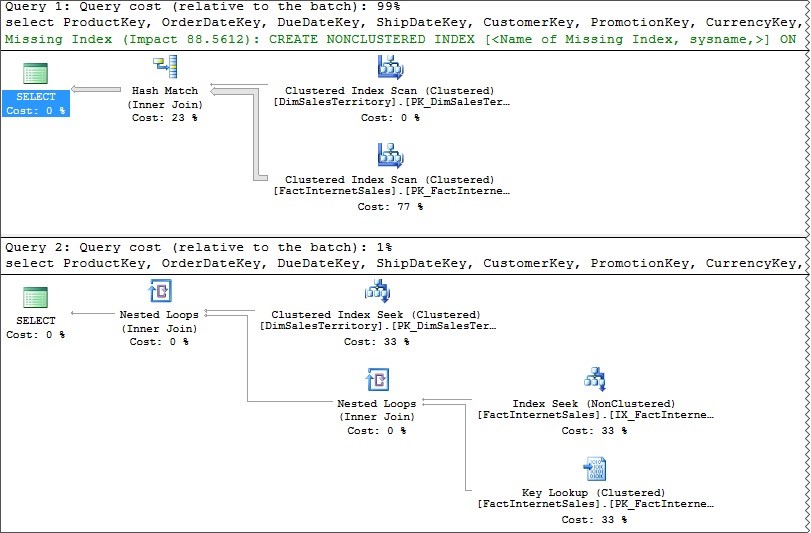
Although these queries return the same data, the plans and performance are very different. Query 1 (predicate written against SalesTerritoryCountry) estimates too high and chooses a much larger plan than it needs. It doesn’t have a clue that there are zero rows for SalesTerritoryCountry = ‘NA’.
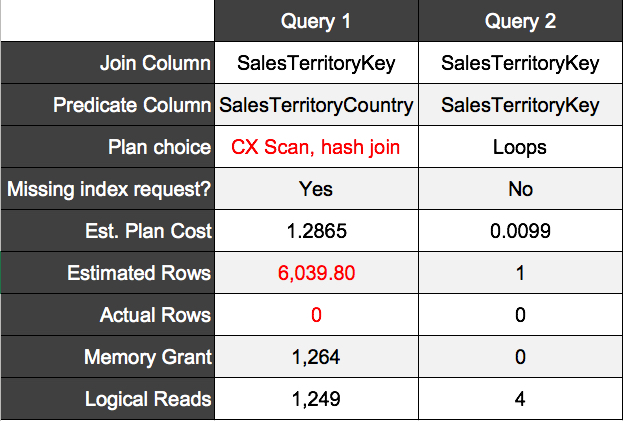
Hash joins aren’t necessarily bad, but we don’t need one for this query. Why do the heavy lifting for no rows?
SQL Server uses statistics for estimates. It’s using them for both of these queries, just in different ways. For the query “where st.SalesTerritoryCountry = N’NA’”, it uses two statistics:
dbo.DimSalesTerritory This is a small dimension table. SQL Server uses a column statistic on the SalesTerritoryCountry column. It’s able to look the value NA up in a detailed histogram that describes the data distribution to see that there’s just one row for that value in the table. Super simple!
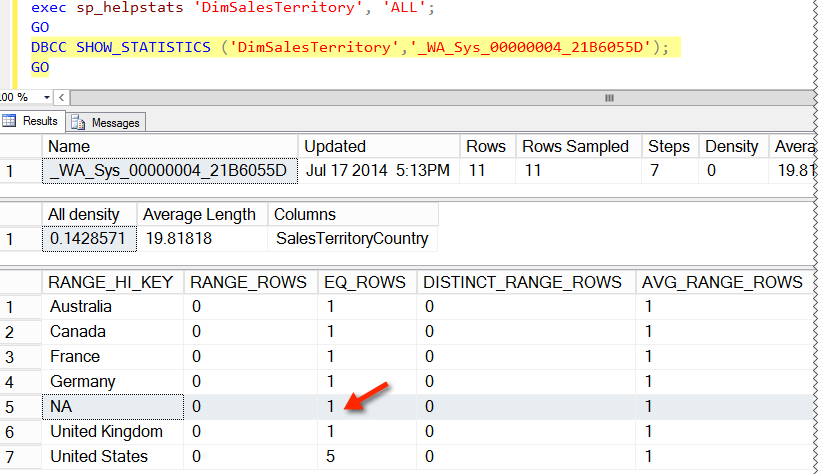
dbo.FactInternetSales Things get more complicated here. The FactInternetSales table doesn’t know anything about SalesTerritoryCountry. It only has the column SalesTerritoryKey.
And although it’s joining on the column, it doesn’t understand that the SalesTerritoryCountry = NA is the same thing as SalesTerritoryKey = 11.
Query optimization has to be fast, and SQL Server has to figure everything out before it begins executing the query. It doesn’t have the ability to go run a query like “SELECT SalesTerritoryKey from dbo.DimSalesTerritory WHERE SalesTerritoryCountry = N’NA’” before it can even optimize the query.
So it needs to make a guess about how many rows an unknown Country has in FactInternetSales.
It does this using a part of the statistics called the “Density Vector”. SQL Server has statistics on an index that I created on the SalesTerritoryKey column in this case. The density vector describes how many rows on average any given SalesTerritoryKey has associated with it in the fact table.
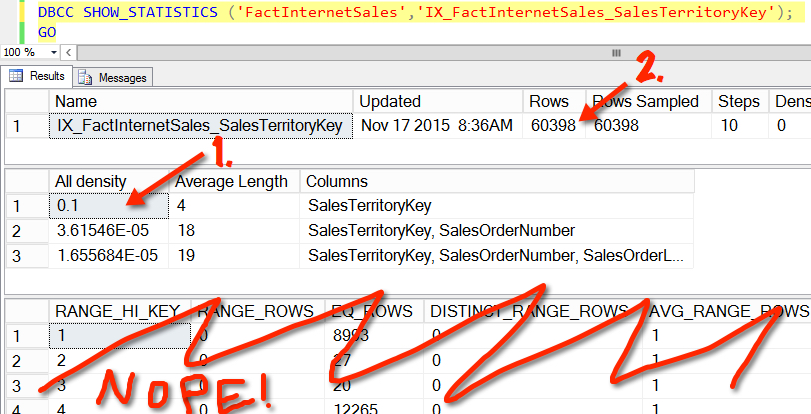
The average density is .1 and there are 60398 rows in the table. 60398 * 0.1 = 6039.8 … there’s our row estimate!
In this case, 6,039.8 rows is enough that SQL Server decides that many nested loop lookups would be a drag. It decides to build some hash tables and figure it out in memory. Honestly, it’s not a terrible choice in this case. Yeah, it needs a memory grant, but it gets the work done in a very small amount of milliseconds and calls it a day.
If this was just one part of a much larger and more complex plan, it could have much bigger consequences, and make a more significant difference in runtime.
Notice that on Query #2, I wrote the predicate against the dimension table, not the fact table. It was able to see that I joined on those columns and use that predicate against the fact table itself to get a very specific estimate.
That’s pretty cool!
Whenever you have a chance to simplify a query, it can be beneficial.
In this case, if we’re writing a predicate against the SalesTerritoryKey column, it’s fair to ask if we need to join the two tables at all. If we have a checked foreign key that ensures that every SalesTerritoryKey has a matching parent row in DimSalesTerritory and we don’t actually want to return any columns from DimSalesTerritory, we don’t even need to do the join.
In complex situations when performance is important, thinking carefully about how you write queries and where you put predicates can sometimes help you tune.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.