Msg 195: STRING_SPLIT Is Not a Recognized Built-In Function Name
Yesterday, I was writing some Transact SQL to dust off the cobwebs. I got confused when I was playing around with the STRING_SPLIT function, and kept …
Read MoreYou’re designing table partitioning, or you want to make a change to an existing partition function. It’s critical to understand the difference between how “left” and “right” partition functions behave, but the documentation is a bit confusing on this topic.
Honestly, even after years of working with partitioning, it’s easy to get confused about left and right after you think about something else for thirty seconds.
This is explained in Microsoft’s documentation with some tables. But for me, diagrams make this MUCH easier.
This is not as much fun as an all-inclusive resort. But know that boundary points are always “included” with a partition.
Left based partitions are the default, if you don’t specify whether you want left or right. Here’s an example using a DATETIME2 data type with precision 7:
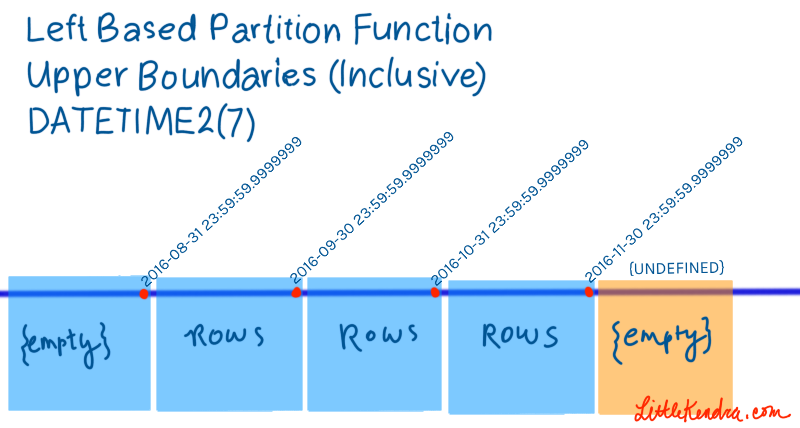
Left based partitioning can require being particularly nitpick-y if you’re working with the DATETIME or DATETIME2 data types. For example, if you’re partitioning by month, you typically don’t want the first moment of a month to be physically stored with data from the previous month– so you have to specify the last second of the last hour of the last day of the month at the boundary point. (Related fact: DATETIME is peculiar because it rounds microseconds to increments of 0, 3, and 7)
Right based partitions are simpler to define when it comes to DATETIME and DATE types, because every day begins at midnight and every month begins on the first.
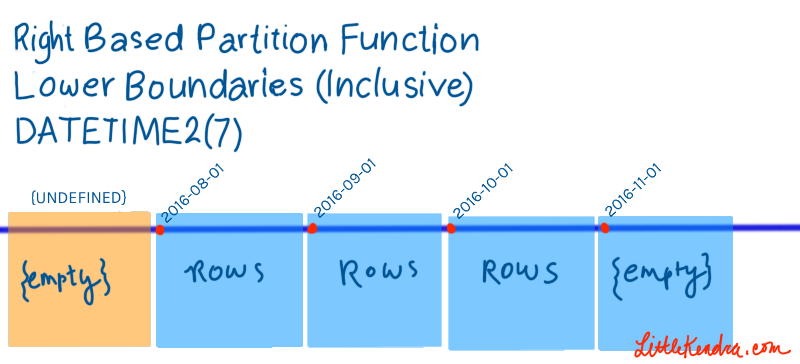
It’s a best practice to [keep the partitions at the ends of your table empty](https://technet.microsoft.com/en-us/library/ms186307.aspx#Best Practices). This keeps your life simpler if you’re going to be adding (splitting) or removing (merging) partitions at the ends of your table.
Honestly, I don’t have a huge preference these days. Either of them can be a big old pain if you mess up your boundary points, or let data “spill” into a location it shouldn’t because you forgot to keep empty partitions at the end of the table, particularly if you’re using a complex filegroup setup.
So I recommend using whichever seems more straightforward for your data type and scenario. Just make sure that if you’re doing sliding window, or merging/splitting partitions for any reason, that you test all that code and make sure that you’re not accidentally causing data movement that will become painful when your data sizes grow.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.