
Msg 195: STRING_SPLIT Is Not a Recognized Built-In Function Name
Yesterday, I was writing some Transact SQL to dust off the cobwebs. I got confused when I was playing around with the STRING_SPLIT function, and kept …
Read MoreI recently got a table partitioning question from a reader:
We now need to load some historical data into the table for 2013 so I want to alter the function and schema to add monthly partitions for this. But I can’t work out how to do this using SPLIT? Every example and tutorial I’ve looked at shows how to add new partitions onto the end of a range, not split one in the middle.
They sent along their partition function and scheme. It’s a LEFT based partition function, so the partitioning boundary points are “upper” boundaries. The partition function was set up using an INT data type with an interesting approach: they made the boundary points invalid dates, like 20161100.
Basically, it looks something like this:
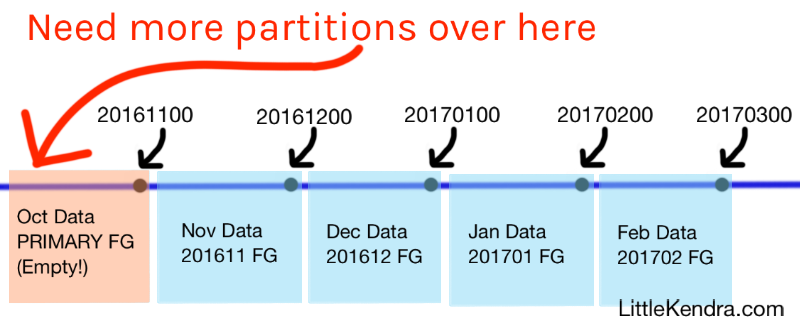
In my diagram, I show that we have data starting in November, because I’m simplifying the problem. In reality, the person asking the question had data for 2014 through 2018, partitioned monthly. They needed to load historical data for 2013.
You can choose to add partitions on the lower end of the existing table, and I’ll show you how. But you’ve got choices!
Partitioned tables with many billions of rows or hundreds of GB of data become unwieldy over time.
So in some environments, it’s better to have multiple partitioned tables, and use a partitioned view to simplify reading data. This frees you up to add new columns only to the “current” table, and index different tables as you need.
Inserting data into partitioned views can be a bit of a pain, so many people taking this approach use dynamic SQL or a stored procedure to insert or update data into the “current” table, and the use the partitioned view for reads.
On the one hand, it’s good to be consistent. On the other hand, do you really need one filegroup per month?
Maybe you do for some reason.
But maybe your SQL Server’s storage now uses some of that fancy automatic tiering, where less read data automatically goes to slower disks. So maybe the filegroups aren’t useful for performance anymore.
And maybe you rebuild indexes in those filegroups, which results in having empty space in each filegroup… and you could save some storage if you consolidated a bit.
Filegroups can be useful for things like running CHECKDB against a subset of the data, and for restoring databases “piecemeal”. But depending on your storage and your data sizes, you might want to let several partitions of data (or maybe more) share a filegroup.
It’s worth thinking about before you finalize your scripts!
(For the sake of the demo below, I stick with one partition per filegroup to be consistent with what they have.)
There’s really two things we want to fix here:
I created a demo script over on GitHub that creates a database, then creates a partitioned table just like you see above. If you’d like to play along, grab the gist of the whole demo script here.
There’s no way to ALTER the filegroup an existing partition is assigned to. We can remove the boundary point associated with the filegroup, then add it back with the right filegroup, though. Since the partition is empty, this is no big deal in this case. All it takes is this:
ALTER PARTITION FUNCTION [pf_monthly_int] ()
MERGE RANGE ( 20161100 );
GOAdding new partitions is relatively simple. We need to add a new filegroup and file, tell the partition scheme to use that filegroup for the next partition we add, then do a ‘SPLIT’ to add the boundary point.
Here’s the code that makes that happen:
/* OK, let's add that boundary point back and give it a non-primary FG */
/* Create the filegroup and give it a file... */
ALTER DATABASE PartitionSplittin add FILEGROUP [201610];
GO
ALTER DATABASE PartitionSplittin add FILE (
NAME = FG201610, FILENAME = 'S:\MSSQL\Data\FG201610.ndf', SIZE = 64MB, FILEGROWTH = 256MB
) TO FILEGROUP [201610];
GO
/* Add the filegroup into the scheme by setting it NEXT USED */
ALTER PARTITION SCHEME [ps_monthly_int] NEXT USED [201610];
GO
/* Then we can SPLIT */
ALTER PARTITION FUNCTION [pf_monthly_int] () SPLIT RANGE ( 20161100 );
GOWe can repeat that same pattern to keep adding more partitions farther down the table, as far back as we need to go.
I like to use the query here to verify everything looks right.
You don’t have to take my word on this one. It’s right in Books Online on the ALTER PARTITION FUNCTION article:
Always keep empty partitions at both ends of the partition range to guarantee that the partition split (before loading new data) and partition merge (after unloading old data) do not incur any data movement. Avoid splitting or merging populated partitions. This can be extremely inefficient, as this may cause as much as four times more log generation, and may also cause severe locking.
“Severe locking” is about as much fun as it sounds, so always test ahead of time and be safe out there!



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.