Adaptive Joins and Memory Grants in SQL Server
Adaptive joins let the optimizer choose between a Hash Join and a Nested Loop join at runtime, which can be fantastic for performance when row count …
Read MoreHere’s a great recent question that I got about query tuning and index use:
Assuming that the documented levels of data type precedence in SQL Server are true as of SQL 2016, why does a bigint value not force an index scan when compared against an int column?

This query is an example using the large BabbyNames database:
USE BabbyNames;
GO
SELECT COUNT(*)
FROM dbo.FirstNameByBirthDate_1966_2015
where FirstNameId = CAST(50576 as bigint);
GORunning this query, sure enough, we get a nice, efficient index seek:

It seeks straight to the 440 rows that it finds for this. Looking at the properties of the seek operator, it read exactly 440 rows– no muss, no fuss, no waste.

It’s true! According to Books Online, BIGINTs have a precedence of 15 and INTs have a precedence of 16. And right at the top of the page it says:
When an operator combines two expressions of different data types, the rules for data type precedence specify that the data type with the lower precedence is converted to the data type with the higher precedence.
That would make this seem like one of those cases where every row in the table will need to be converted to a BIGINT in order to do the comparison. That would require reading every row in the index.
And there’s a lot more than 440 rows.
Let’s say our query was a little different…
CREATE INDEX ix_FirstNameByBirthDate_1966_2015_StateCode on
dbo.FirstNameByBirthDate_1966_2015 (StateCode);
GO
SELECT COUNT(*)
FROM dbo.FirstNameByBirthDate_1966_2015
WHERE StateCode = CAST('OR' AS NCHAR(2));
GOHere, we have a nonclustered index on StateCode.
Our query is counting rows for the state of Oregon. But we’ve cast ‘OR’ as an NCHAR type – the ‘N’ at the beginning means this type supports unicode, and requires two bytes for each column. Unicode types support a wider range of characters than non-unicode types.
But the StateCode column is CHAR(2).
NCHAR has a precedence of 26, and CHAR has a precedence of 28. We are comparing a higher-precedence value (which holds more information) to a lower precedence column.
Looking at the plan, this type we DO get an index scan!

This time the number of rows read is 159,405,121: all the rows in the index.
If we look at the properties of that warning sign, SQL Server says that it must do an implicit conversion on the table column StateCode to compare it to the value we passed in.
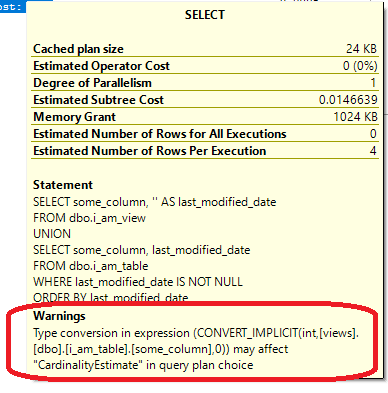
When I read this question, I remembered an awesome blog post by Jonathan Kehayias. Back in 2013, he tested out a bunch of different type conversions. He mapped out which comparisons cause a seek, and which cause a scan. He even tested under more than one collation!
Read Jonathan’s post, ‘Implicit Conversions that Cause Index Scans’ to see the cool charts.
In the top chart, you see what we saw in our (much simpler) test:
Technically the top chart uses the SQL_Latin_General_CP1_CI_AS collation, and I’m using the case-sensitive version of that, but they behave the same in these cases.
Another great blog post by Paul White gives some clues as to why this might be. In, “Join Performance, Implicit Conversions, and Residuals,” he writes about something slightly different: joining two columns of different types. But along the way Paul mentions that there are ‘families’ of data types.
INT and BIGINT are in the same type family. This is the comparison that worked fine and allowed a seek on the value.
CHAR and NCHAR are not in the same type family. This is the comparison that forced an index scan.
I don’t know of a place where this is discussed in Microsoft documentation, but Jonathan and Paul’s posts both show that it’s not as simple as the precedence of individual types.
Sometimes we get lucky comparing a literal value to a column of a different type.
But this is very complicated, and joining on two columns of different types in the same family without explicitly converting the type of one of the columns resulted in worse performance in Paul White’s tests, when the columns allowed NULLs! (Note: I haven’t rerun those tests on 2016, but I think the general advice below still applies.)
General advice: don’t rely on being lucky. Pay attention to your data types, and compare values of the same data type wherever possible.
I show another example of data type comparisons gone wrong in the course, Tuning Problem Queries in Table Partitioning.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.