Bad News, DBAs, We Are All Developers Now
I sometimes joke that I’m a Junior Developer and a Principal Database Administrator, which is why I have a Staff level title. I’m not sure …
Read MoreMost of the time in SQL Server, the MAX() function and a TOP(1) ORDER BY DESC will behave very similarly.
If you give them a rowstore index leading on the column in question, they’re generally smart enough to go to the correct end of the index, and – BOOP! – just pluck out the data you need without doing a big scan.
I got an email recently about a case when SQL Server was not smart enough to do this with MAX() – but it was doing just fine with a TOP(1) ORDER BY DESC combo.
The question was: what’s the problem with this MAX?
It took me a while to figure it out, but I finally got to the bottom of the case of the slow MAX.
Dear readers, it is not always a good idea restore database backups from strangers on the internet. People can put nasty things in there, just like any old thing you zip up and attach to an email.
But this backup was from a fellow Microsoft MVP, I was curious about the problem, and I have a nice, isolated test instance in a VM just waiting to be tormented. So I went forth and restored!
Sure enough, I could reproduce the issue.
Here’s what it looked like – but in a fake table that I’ve created from scratch, which reproduces the issue.
Here is the actual plan for the problem query (view from Sentry One’s free Plan Explorer)
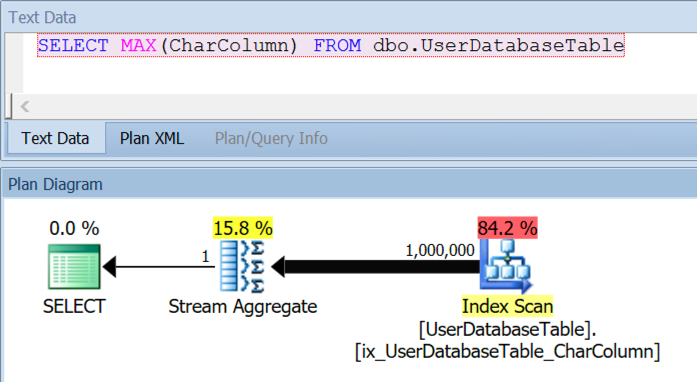
That nonclustered index leads on CharColumn. SQL Server correctly estimated that there are 1 million rows in the index and it fed them all faithfully into a Stream Aggregate operator to do the MAX.
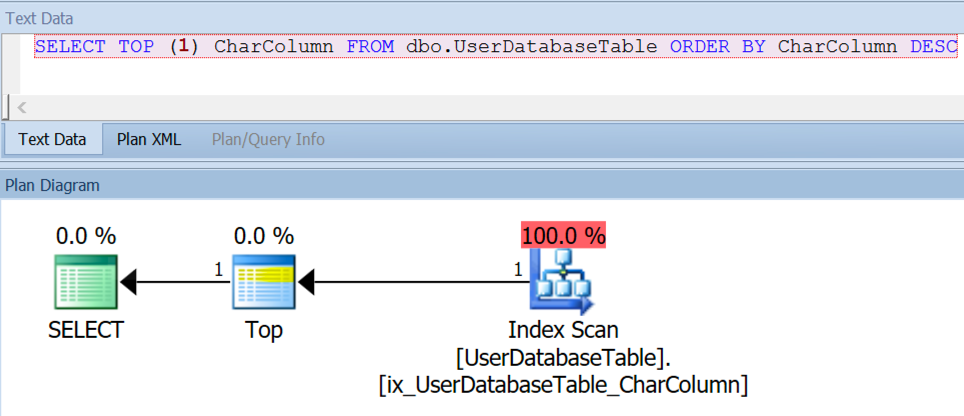
Fast query used the very same index. It figured out that it could go to one end of the index and do a quick backward scan, feeding that TOP 1 row into a TOP operator and then stopping.
And it was correct. One row read, not one million!
SQL Server estimated that this MAX query was going to be more expensive than the TOP, and it was right:

These metrics are for the queries in a simple, narrow table with a single column nonclustered index on CharColumn. Add more rows and more complexity, and the performance difference will just get uglier.
The first thing I noticed is that we’re doing MAX against a CHAR column. CHAR is a fixed length, non-unicode data type.
Actually, that’s not the first thing I noticed.
The kindly fellow who raised this question let me know right away that his question is regarding a Dynamics database. That was one of the initial things that forewarned me that things might get wacky.
Having done some consulting for a while, I know the look that SQL Server specialists get when confronted with any database that’s a member of the Dynamics family.

It’s not that Dynamics is bad, it’s just … weird. The kind of weird that can lead you to think that your database is haunted, because it gets unusual behaviors related to its strange habits. (Heaps, odd settings, strange creaks in the night…)
Strange things like this issue.
But we can figure out EVEN A DYNAMICS query tuning problem, right? YES, WE CAN!
The very first thing I tested was whether or not this “scan all the rows and push them into a stream aggregate for MAX” issue happened against other CHAR columns.
I selected CHAR data from another table in another database into a new table in my test database, indexed it, and started querying it.
It worked fine - the MAX() plan estimated one row into a top operator, then fed that single row into a stream aggregate.
I made the CHAR data into a CHAR(13) column, same as the test table.
It worked fine, too.
I spent about half an hour testing random things, that didn’t end up helping. Things like….
Sorry, dog, I have one last thing to test.
The problem CHAR column didn’t allow nulls. In the documentation for MAX, it mentioned that it skips NULL values. The column seemed perfectly attuned to that, but I thought, hey, maybe switch that on my test column and see what happens?
So I ran this command:
ALTER TABLE dbo.UserDatabaseTable
ALTER COLUMN CharColumn char(13) NULL;
GOI didn’t change the column length, I just made it allow NULLs.
After this, when I re-ran the MAX query, the plan looked like this:
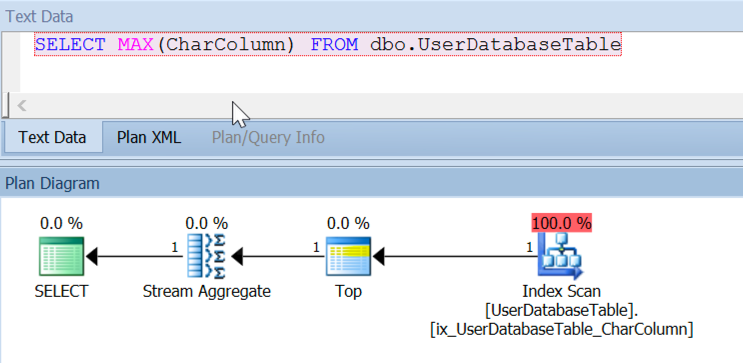
This is what we wanted our MAX() query to do all along – feed a row into a TOP operator. Yes, we still have a stream aggregate there, but it’s a lot faster when it’s only getting one row.
This query took 0 seconds of CPU time and did 3 logical reads. It now matched the performance for the TOP(1) / ORDER BY query.
I was making progress, but this was still really fishy. After all, MAX does not count NULL values, so if the column didn’t allow NULLs, that seems like it would make MAX’s job easier, not harder.
So I wondered if it was just the act of altering the column that made the difference, not changing the NULL-ability.
I re-restored the database, and I ran:
ALTER TABLE dbo.UserDatabaseTable
ALTER COLUMN CharColumn char(13) NOT NULL;
GOYep, I altered the column to be JUST LIKE it already was.
This also fixed the issue.
It’s not the NULLs, it’s some side-effect of altering the column. I scratched my head, looked at the dog, and called it a night. Relaxation and sleep can be good for this kind of thing.
In the morning, I played around with the table a bit more:
This convinced me that it was nothing about that specific table or that specific database.
This problem is a column problem.
I suspected I was close to the answer at this point, and I got all excited and happy. I could barely type sensible TSQL, but I managed to query sys.columns for the table when it had the problem, and after I fixed it with an ALTER:
SELECT
table_name = OBJECT_NAME(c.object_id),
c.*
FROM sys.columns AS c
WHERE c.object_id = OBJECT_ID(N'UserDatabaseTable')
AND c.name = N'CharColumn';
GOAnd I found the answer.
When this CHAR(13) column has is_ansi_padded set to 0 (false), the MAX() operation generates an index scan that feeds the data into a stream aggregate operator.
The TOP(1) / ORDER BY combo doesn’t care.
MY ALTER TABLE / ALTER COLUMN statements have the effect of setting is_ansi_padded to 1 (true), which is the setting SQL Server generally prefers. With ANSI_PADDING on for the column, SQL Server says, “oh, I don’t need to read every row!” and just goes to the end of the index.
SET ANSI_PADDING OFF; in my session to match my session settings to the column setting doesn't change anything. This is not a problem of session settings mis-matching the column settings, this is a problem with the ANSI_PADDING setting on the column itself.These ANSI settings are weird and esoteric. Here is a summary of ANSI PADDING from “INF: How SQL Server Compares Strings with Trailing Spaces”:
SQL Server follows the ANSI/ISO SQL-92 specification (Section 8.2,
, General rules #3) on how to compare strings with spaces. The ANSI standard requires padding for the character strings used in comparisons so that their lengths match before comparing them. The padding directly affects the semantics of WHERE and HAVING clause predicates and other Transact-SQL string comparisons.
The article has more helpful info, so if you’re curious, go ahead and click through and read it.

We’ve solved the mystery, as far as the MAX() query goes:
But… what about the TOP (1) / ORDER BY query?
Isn’t ORDER BY also comparing values?
Shouldn’t that query also have to look at every row, for the ORDER BY operation? If there’s a bug here, it seems kinda like the TOP (1) / ORDER BY query is the one who is misbehaving.
I found a tiny piece of documentation for this (after I figured it out, of course - isn’t that always the way) in the Books Online article for SET ANSI_PADDING:
When ANSI_PADDING set to OFF, queries that involve MIN, MAX, or TOP on character columns might be slower than in SQL Server 2000.
It does seem from this that TOP/ORDER BY should be padding all the strings before comparing them, I’m pretty reluctant to file a feature request saying I think something should be slower (and for a deprecated setting).
For most folks, the message is: before you create a table, it’s good to make sure you’re using the ANSI settings that SQL Server recommends. Here is a list in the Microsoft documentation. One of them is: SET ANSI_PADDING ON.
In fact, in the case of this Dynamics database, our questioner started looking into this and found that setting ANSI_PADDING to off may no longer be required. WOOT!
If you want to know if any of your existing tables has this problem, you can query sys.columns to find out (like in the query above).
If you’d like to play around with code that reproduces the problem in this mystery, you can grab it here.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.