Your AI Doesn't Need to Dig Around in Production Databases. It Needs Better Briefings.
I increasingly hear or read the advice to solve problems by querying MCP servers on production databases.
Meanwhile, I’m reading output from an …
Read MoreI use Datadog on a regular basis, and I’m a pretty huge fan. The monitoring pack for SQL Server (and its PAAS variants) is still pretty rudimentary, but it evolves regularly. That’s NOT what I’m a fan of, though.
What makes me a raving fan is the flexibility of Datadog’s notebooks and dashboards, combined with the ability to create all sorts of custom metrics and monitors. There are always things in SQL Server monitoring packs that I have strong opinions about. Datadog lets me take what I want, build what I need that isn’t contained in that, and ignore the rest. For a team that has the budget to afford Datadog paired with dedicated database staff with the time and resources to do this work, this can be a great fit.
One of the weirdest and worst parts of the Datadog SQL Server monitoring tooling, though, is how it handles wait stats. In my opinion, it’s a case of someone reinventing a wheel that didn’t need to be reinvented, and then not documenting what they did clearly (at least not in a way I can find).
Two of the most confusing Datadog ‘waits’ are labeled ‘CPU" and “Waiting on CPU”. I opened a support ticket with Datadog a while back to ask what these are, because I couldn’t find any way they correspond to actual wait stats in SQL Server. I learned they aren’t wait stats at all. In fact, I think you should largely ignore them. Here’s why.

The most important thing I learned from the support ticket is that what are listed as “waits” in Datadog are purposefully not just the wait types we are familiar with from SQL Server. They have invented the concepts of “CPU” and “Waiting for CPU”, which are based on query/session status.
What determines the “CPU” and “Waiting for CPU” wait event is a combination of a couple of things:
- The query’s current status (pulled from sys.dm_exec_requests (Transact-SQL)).
- The session’s current status (pulled from sys.dm_exec_sessions (Transact-SQL)).
- The query’s current wait type (pulled from sys.dm_os_wait_stats (Transact-SQL)).
Here’s an image of how Datadog displays so-called CPU “waits” – it’s really prominent:
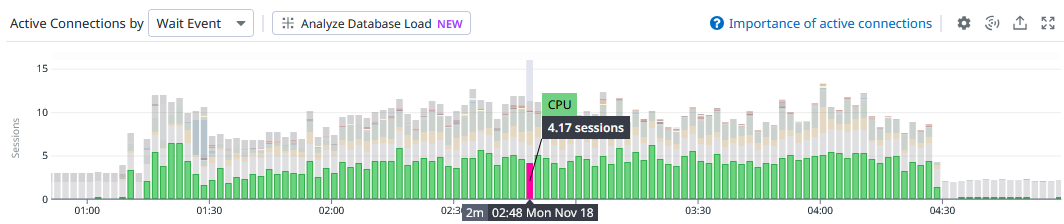
When you look at these graphs, it’s almost impossible to not think this is some kind of representation of a CXPACKET wait or SOS_SCHEDULER_YIELD. However, it’s not that at all:
If the query doesn’t have a wait type and the request status is
runningor if the session status isrunning, then the Wait Event will be CPU.
It’s just a sample of the number of running queries.
Why in the world would that be included as a ‘wait’ and labeled ‘CPU’? I don’t know that anyone did any user research with DBAs here.
For workload/activity metrics, I prefer looking at something like batch requests/second. I don’t find this sample of executing queries at an instant useful, so I ignore it.
I guess it’s a good thing that there’s a similarly named wait, “Waiting on CPU”, because at least that’s a clue that a “CPU” wait isn’t the same thing in some way? I donno. Here’s what “Waiting on CPU” looks like:
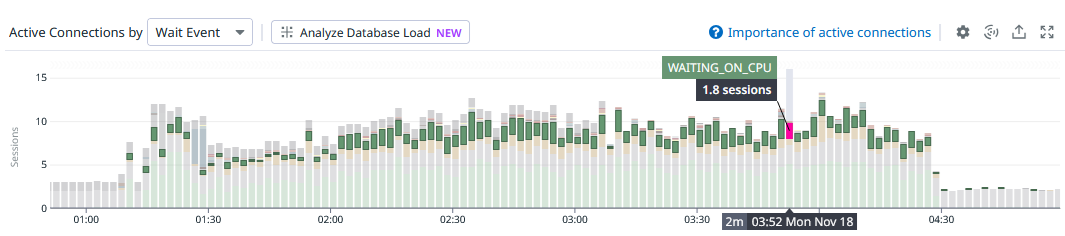
This so called “wait” represents a query that is in the runnable queue that isn’t running at the instant of the sample:
If the query doesn’t have a wait type, and the request status is
runnable, then the Wait Event will be WAITING ON CPU.
I don’t think this is particularly useful, either. The SQLOS cycles queries on and off the runnable queue very, very frequently. What’s sampled at an instant like this isn’t super meaningful to me.
My take: One of the benefits of SQL Server is that it has very strong documentation and an ecosystem of users who generate a lot of content about things like wait stats. Just show us the waits with their actual names, don’t rename them or decode them. Don’t make stuff up. That’s really all you need to do. Renaming things and making up “waits” to inject into graphs with confusing names only makes it harder for users to understand your tool.
But like I said– I love using Datadog. While I don’t find the way it displays SQL Server wait stats super useful, the flexibility of the tooling makes it OK for me to disagree with their take on that and still build observability tooling that does what I need by filtering for the waits I care about and setting up custom metrics that help me alert quickly on problematic situations– plus I can build in self-healing. And that, dear reader, is glorious.
Thanks very much to Datadog support for helping me decode this when the answer wasn’t clear at all.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.