Bad News, DBAs, We Are All Developers Now
I sometimes joke that I’m a Junior Developer and a Principal Database Administrator, which is why I have a Staff level title. I’m not sure …
Read MoreThis post is part of TSQLTuesday #140, “What have you been up to with containers?”
Disposable databases are indispensable for software developers, both for initial development work and in automation pipelines. Containers pair exceptionally well with temporary databases and provide a lightweight mechanism to spin up an environment on demand.
In this post, I share why we need disposable databases, use cases for disposable databases in automated workflows, and a tutorial to create an Azure DevOps pipeline to spin up an AdventureWorks2019 sample data container on demand using Spawn. Spawn has a free tier which you can try out anytime.
There are two main reasons why we need disposable databases for software development:
Testing database changes requires a realistic dataset. Schema isn’t enough! Will that unique index create successfully in production? Can you add a non-nullable column to that table without a default value? How will this query perform? We need realistic datasets for these scenarios and more.
Databases generally don’t have good ways to “reset” after you make changes. I say “good” here because some techniques do exist. SQL Server, for example, has a database snapshot feature. One can create a database snapshot at a point in time, make some changes, and later revert to that snapshot. But this feature doesn’t scale for software development. Database snapshots aren’t portable: they are tightly coupled with the source database. Database snapshots are read-only for a point in time: they are not writeable. The database snapshot feature is also cumbersome to implement and wasn’t designed with automation in mind.
Without disposable databases, it is much harder to do quality testing of changes. It’s also much harder to validate deployments when reordering changes in release pipelines.
Redgate’s Foundry team created Spawn to explore how a containerized service can solve the problems above. The Spawn cloud service lets users:
These are just the basics. There is a lot more functionality available, including resetting containers and graduating containers to new images.
When your repository contains database code, it’s essential to ensure the code is valid, just like any other code. Disposable databases allow you to automate code validation for your database code whenever someone commits or merges changes into a code branch. Continuous Integration can call a pipeline or action which will:
One example of using a disposable database in an automation pipeline is in a Pull Request (PR) workflow when using Git. In this workflow, a developer will:
There is often an option for automation to kick off at this point to validate the code in your branch. Effective automation will save work for the folks reviewing your Pull Request while enabling them to do high quality review of your changes. If you have a database cloning solution, this automation can:
Optionally, you can keep the database around for the reviewers to inspect as part of the PR review. Many teams prefer to build an entire environment (database, application components, etc.) for use in PR reviews.
All of the accounts, services, and tools used in this tutorial offer free tiers. To follow along, you need:
spawnctl auth in a terminal.Note: We won’t deploy database code to the data container in this tutorial itself, but we’ll set the foundation to do that in a future tutorial.
In this example, I am working with a newly created Azure DevOps project. I’ve initialized the default Git repo with a readme, but I haven’t added any code.
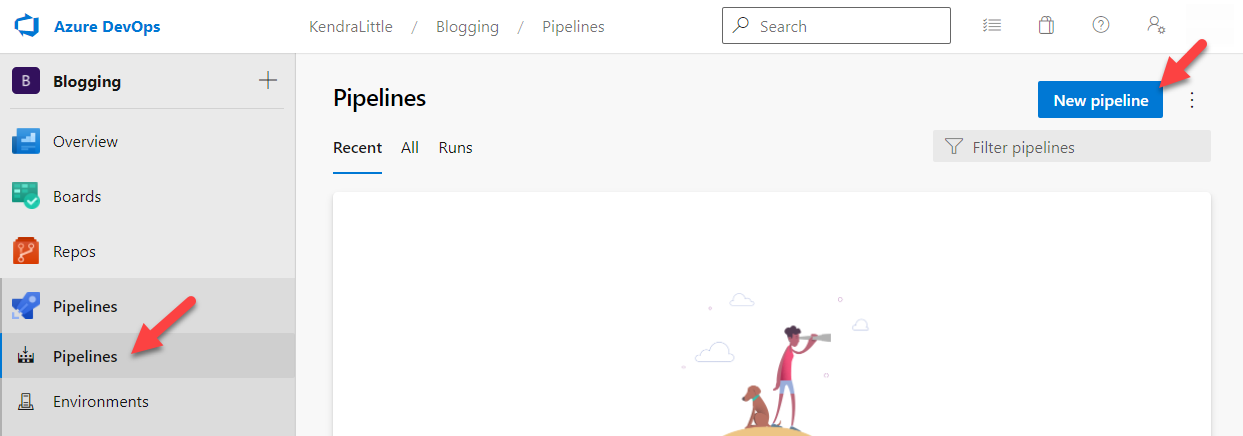
First, click Pipelines in the left menu bar, then click New pipeline at the top right.
At the Where is your code? prompt, click Azure Repos Git. This is a YAML pipeline. (You could also do this process with code stored in Bitbucket Cloud or GitHub.)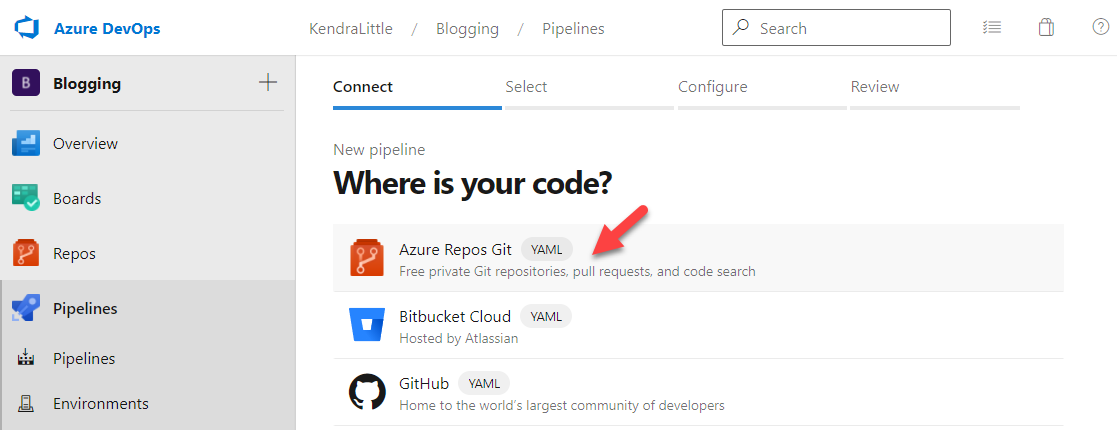
At the Select a repository prompt, click on the name of the repo.
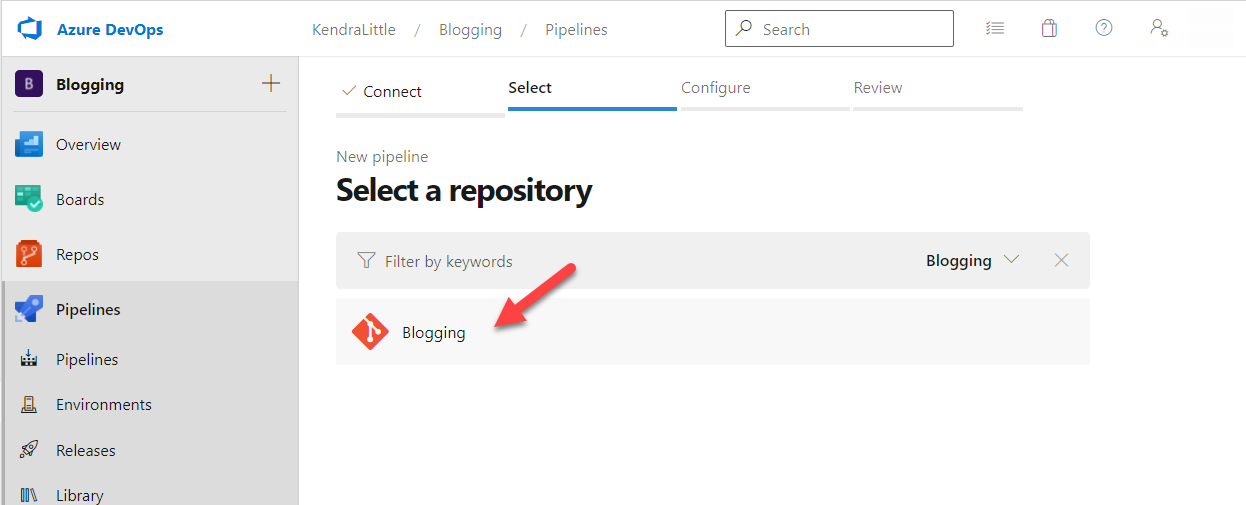
Troubleshooting: If you do not see a repo name here and this is a new Azure DevOps project, click on Repos in the left bar. If it says “[YourRepoName] is empty. Add some code!” at the top, one way to get it working fast is to scroll to the bottom of the page and click Initialize with the “Add a README” option ticked.
At the Configure your pipeline prompt, select Starter pipeline.
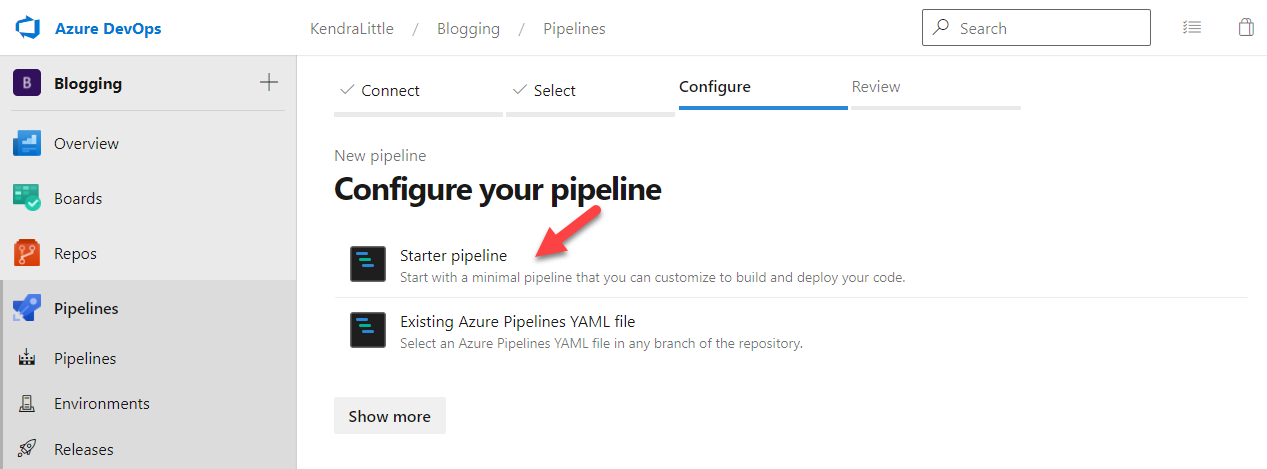
This should bring you to the Review your pipeline YAML screen, with simple starter code in a YAML pipeline.
Our next step is to replace that starter pipeline code with the following YAML. This YAML will…
trigger:
- main
pool:
vmImage: ubuntu-latest
# variable: $(SPAWNCTL_ACCESS_TOKEN) - https://docs.spawn.cc/commands/spawnctl-accesstoken-get
# Variable: $(DATA_IMAGE_NAME) - to test quickly use a public image https://docs.spawn.cc/other/public-data-images
steps:
- script: |
echo "Downloading and installing spawnctl..."
curl -sL https://run.spawn.cc/install | sh
displayName: Install spawnctl
- script: |
set -e
export PATH=$PATH:$HOME/.spawnctl/bin
dataContainer=$(spawnctl create data-container --image $(DATA_IMAGE_NAME) --lifetime 20m -q )
echo "##vso[task.setvariable variable=dataContainerName]$dataContainer"
dataContainerJson=$(spawnctl get data-container $dataContainer -o json)
port=$(echo $dataContainerJson | jq -r .port)
host=$(echo $dataContainerJson | jq -r .host)
user=$(echo $dataContainerJson | jq -r .user)
password=$(echo $dataContainerJson | jq -r .password)
displayName: spawn a database
env:
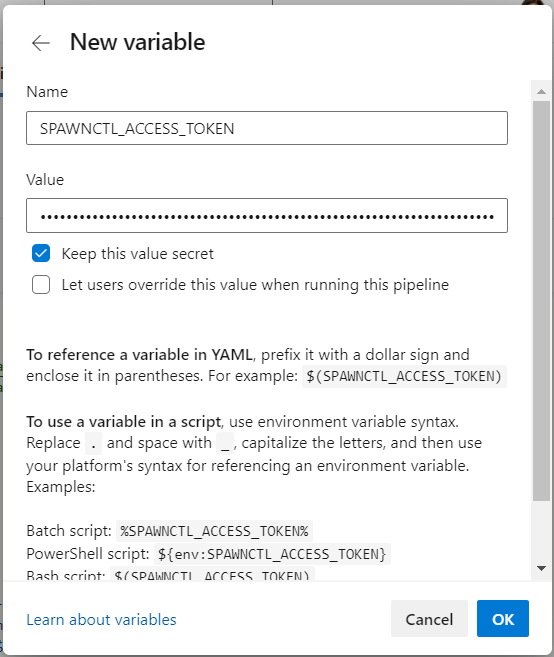
SPAWNCTL_ACCESS_TOKEN: $(SPAWNCTL_ACCESS_TOKEN)On the Review your pipeline YAML screen, click Variables in the top right corner.
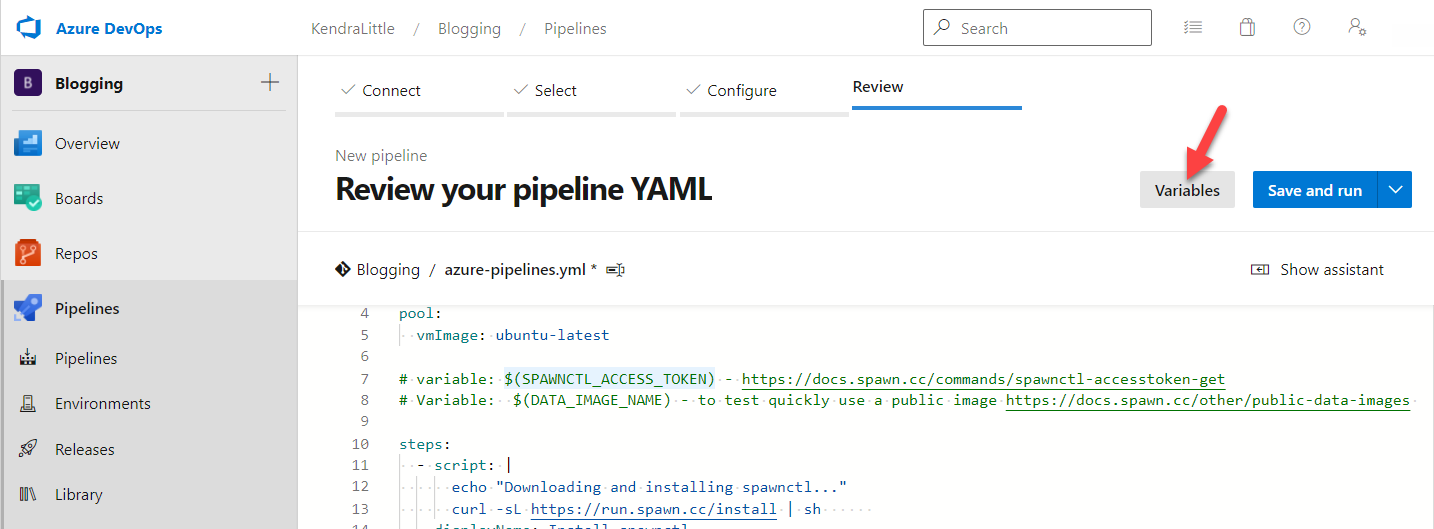
In the Variables pane, click New Variable
Add a new variable:
Click OK at the bottom of the pane.
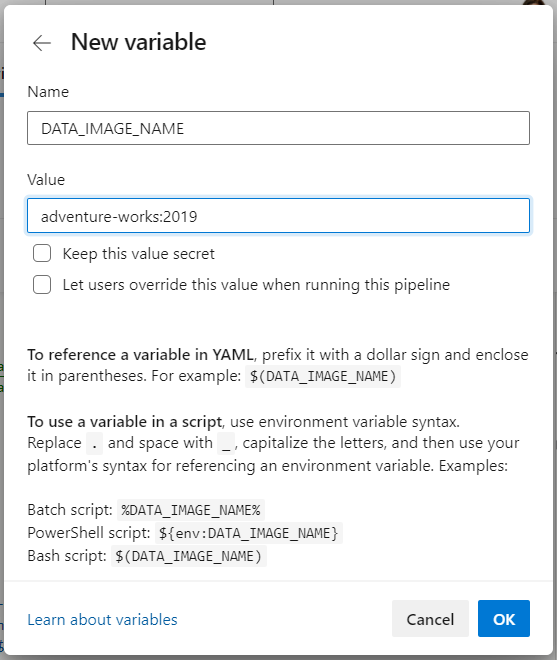
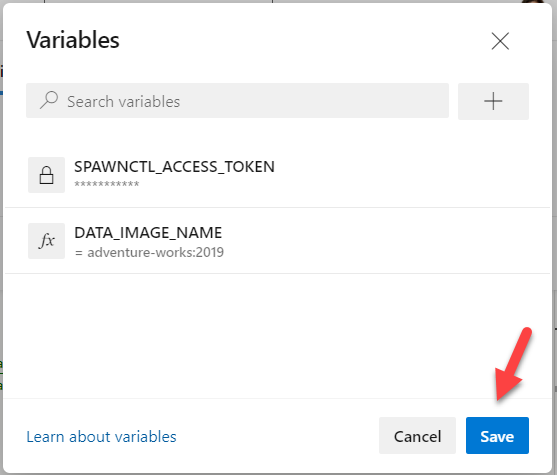
In the Variables pane, click the plus sign to add a second variable.
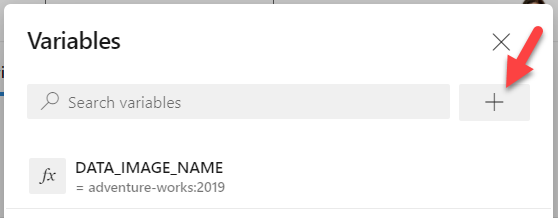
To get the value for this variable, you need to:
spawnctl auth in a terminal.)spawnctl create access-token --purpose "Spawn access token for pipeline test"Copy the token from the terminal to your clipboard.
Now, back in the Azure DevOps variables pane, add a second variable:
Click OK at the bottom of the pane.
Back in the main Variables pane, click Save at the bottom of the screen.
As a quick recap, so far we have:
Now we need to save the pipeline itself. On the Review your pipeline YAML screen, click Save and run.
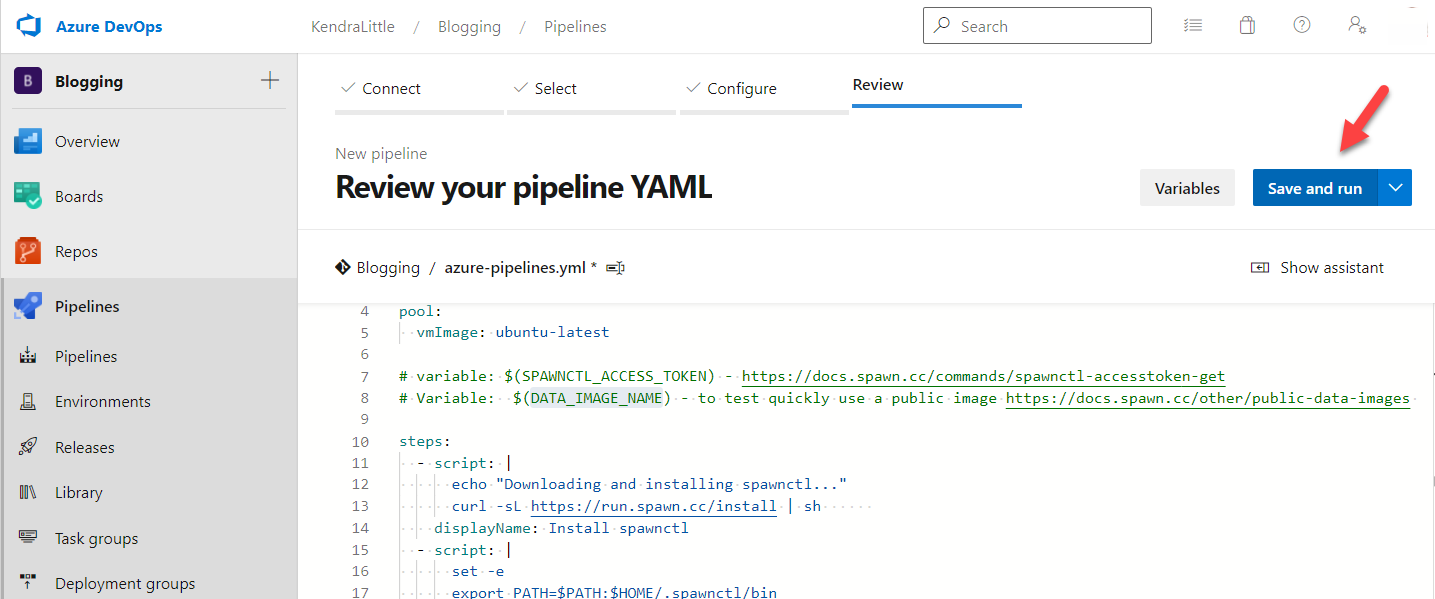
In the Save and run pane which appears, click Save and run in the bottom right corner.
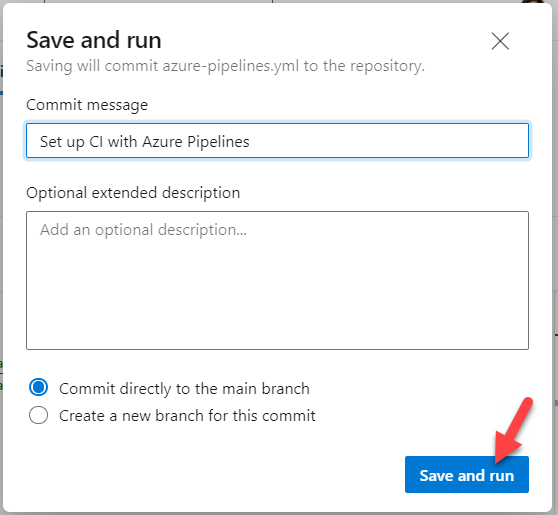
You will now be taken to a screen where you can watch your Pipeline job be queued and then run. If all has gone well, you should see your job succeed in a relatively short amount of time.
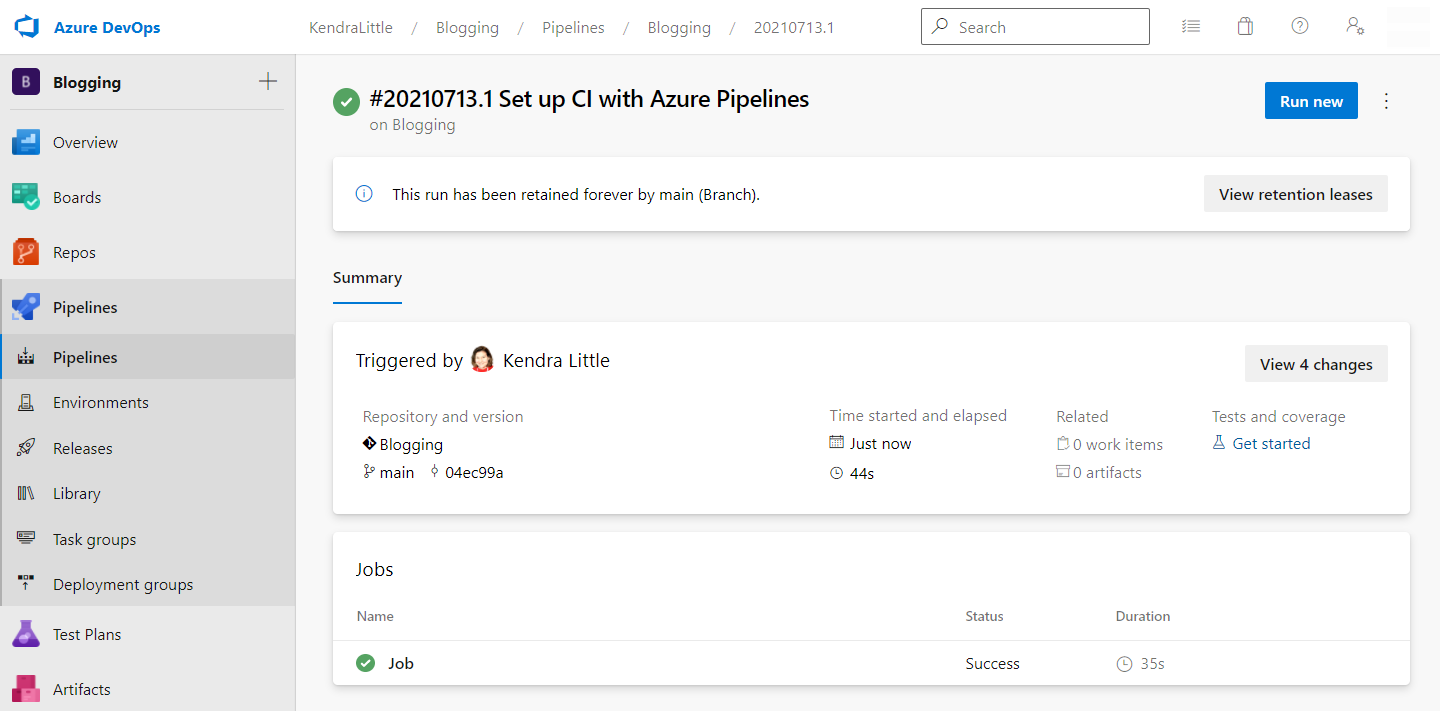
Our pipeline asked Spawn to create a copy of the AdventureWorks sample database with a lifetime of 20 minutes. We can connect to that database in SQL Server Management Studio or Azure Data Studio if we’d like to check it out.
We let Spawn name the database container in this case.
Open a terminal, and run the following command to get a list of all your data containers.
spawnctl get data-containersThis will return a list of your containers with their metadata.

Next, plug the name of your data container into the following command.
spawnctl get data-container adventure-works-ebnmatep -o jsonThis will output connection information for your database.

Note from the output:
You can use this information to connect to the SQL Server instance using the IDE of your choice.
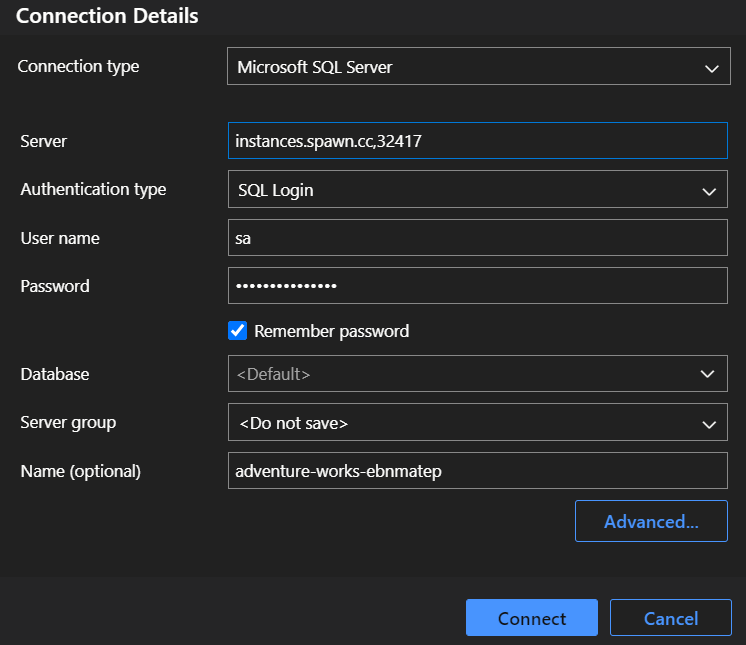
If you enjoy using Azure Data Studio, the Spawn extension for Azure Data Studio makes connecting to your Spawn instances simple.
If you’d like to play around with Spawn locally, follow the Spawn Getting Started tutorial.
If you’d prefer to use Spawn with GitHub Actions, there’s a tutorial for that as well.
I’ve wanted to write this article for a while, but I kept not getting around to it. Thanks to Anthony Nocentino for the writing prompt.



Copyright (c) 2025, Catalyze SQL, LLC; all rights reserved. Opinions expressed on this site are solely those of Kendra Little of Catalyze SQL, LLC. Content policy: Short excerpts of blog posts (3 sentences) may be republished, but longer excerpts and artwork cannot be shared without explicit permission.